
http协议发展历史
HTTP协议发展史
目录
HTTP 0.9
HTTP 0.9是HTTP协议的第一个版本,发布于1991年,非常简单。
请求特性
- 请求方法:只支持GET方法
- 请求头:不支持请求头
响应特性
- 响应信息:只支持纯文本,不支持图片
- 无连接/短连接/非持久连接:利用完TCP连接之后会立即回收
- 无状态:一个HTTP协议的请求无法标识自己的身份
工作原理
HTTP协议通信流程:
- 先建立TCP连接
- 客户端发送请求包
- 服务端收到后发送响应包
- 服务端一旦发送完响应包之后,立即主动断开TCP连接
- 下次HTTP通信还需要重新建立TCP连接
存在的问题
无连接/短连接问题:
- 同一个用户在短期内访问多次服务器,大量时间消耗在重复创建TCP连接上
- 在高并发场景下,对服务端消耗大,客户端访问速度慢
无状态问题:
- 如果是登录状态,HTTP协议无法保存
- 每次请求都需要重新输入账号密码认证
注意:在0.9时代,这两个问题都不是主要问题,因为当时的应用场景简单。
HTTP 1.0
HTTP 1.0发布于1996年,引入了许多重要特性。
请求特性
- 请求方法:支持GET(查)、POST(改)、DELETE(删)、PUT(增)
- 请求头:支持请求头
响应特性
- 响应信息:支持超文本
- 缓存:支持缓存机制
面临的问题与解决方案
1. 无连接/短连接问题
问题:
- 同一个用户在短期内访问多次服务端,大量时间消耗在重复创建TCP连接上
- 高并发场景下对服务端消耗大,客户端访问速度慢
目标:
- 同一个用户在短期内访问多次服务端,能够共用一个TCP链接
解决方案:持久连接/长连接(Keep-Alive)
实现方式:
- 客户端在发送HTTP请求时,在请求头里带上
Connection: keep-alive参数 - 服务端的
keepalive_timeout设置要大于0 - 服务端收到后读取该参数,保持与客户端的TCP连接一段时间
- 响应时也会在响应头里包含
Connection: keep-alive参数 - TCP连接会保持一段时间直到达到服务端设置的
keepalive_timeout时间
补充说明:
- 在HTTP 1.0协议中需要手动添加
Connection: keep-alive参数 - 在HTTP 1.1协议中所有请求都会自动加上
Connection: keep-alive - 服务端也需要相应配置(
keepalive_timeout设置大于0)
2. 无状态问题
问题:
- 服务端无法标识一个HTTP请求的唯一性
- 导致用户登录状态无法保存,每次请求都需要重新认证
目标:
- 让客户端每次发请求时都能标识自身的唯一性
解决方案:Cookie、Session、JWT
状态管理方案
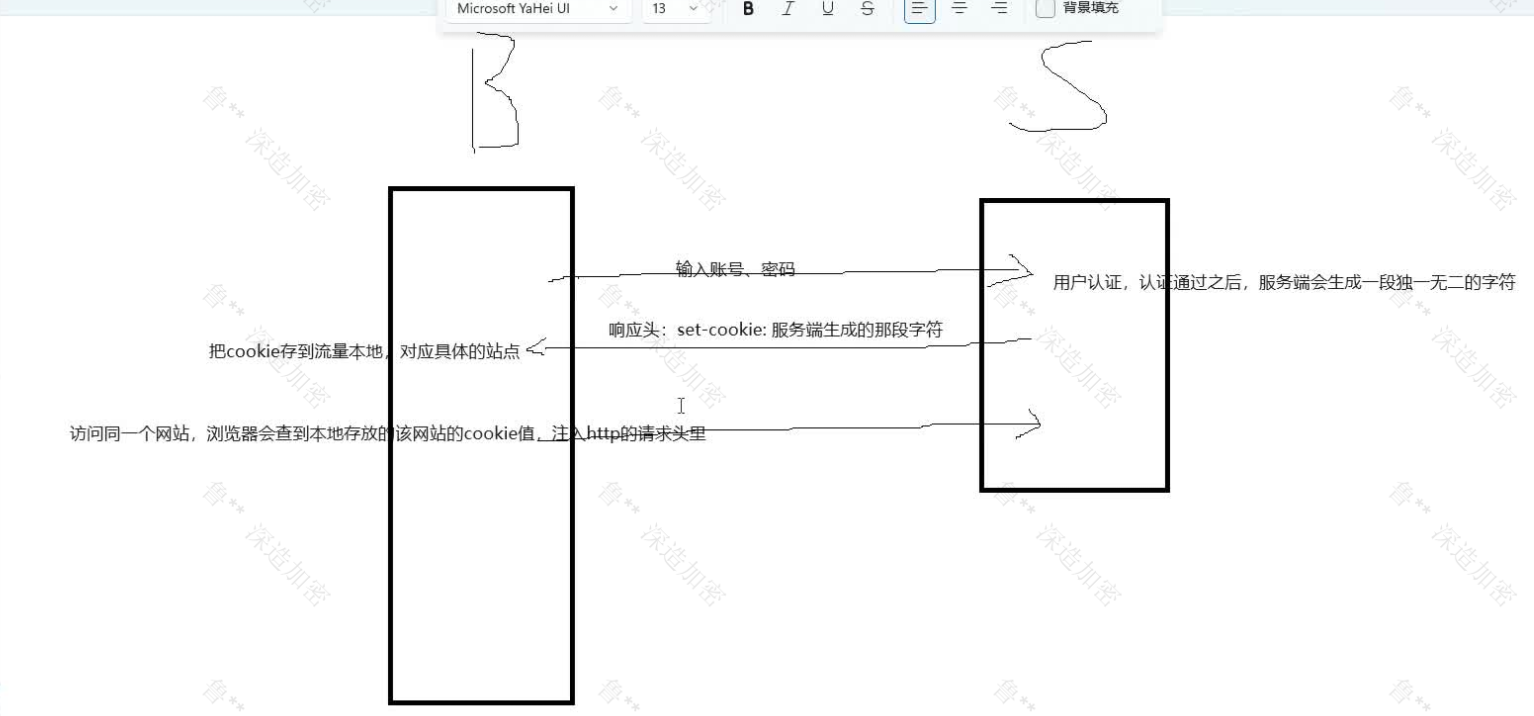
1. Cookie机制
工作流程:
- 访问一个站点,服务端返回的响应头会设置
Set-Cookie: k1=v1; k2=v2 - 浏览器收到后,根据Set-Cookie设置存入本地的Cookie值
- 下次请求该网站,浏览器从本地Cookie取出值,放到HTTP请求的Cookie字段中
特点:
- Cookie是浏览器的功能,存放在客户端
- Cookie存放的内容可以被客户端篡改
2. Cookie + Session机制
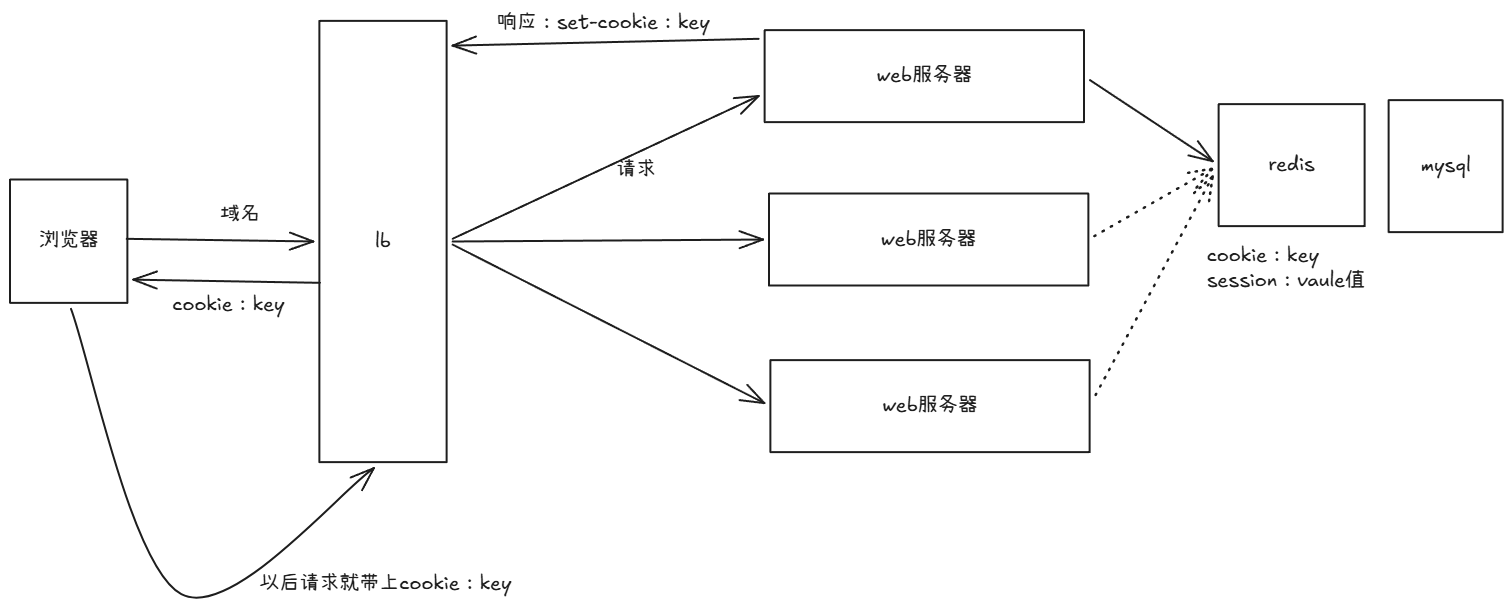
工作流程:
- 访问站点,输入账号密码认证
- 服务端认证通过后,产生标识身份的数据(value)
- 为这些数据关联一个key,形成 key:value 对
- key给客户端存入Cookie,value放在服务端称为Session
- 服务端把key放入Set-Cookie返回给客户端
- 客户端把key存入本地Cookie
- 下次请求时带着key,服务端根据key取出value验证身份
特点:
- 保密数据放在服务端(Session),防篡改
- 集群场景下需要做会话共享(通常存入Redis)
- 会话共享会影响集群的扩展性
3. JWT(JSON Web Token)
工作原理:
- 服务端将状态信息进行加密,加密数据放入客户端的Cookie中(称为Token)
- 下次请求从Cookie中取出Token发送给服务端
- 服务端用加密算法解密验证
特点:
- 优点:不需要做会话共享,安全性高
- 缺点:无法主动废弃某个Token,只能等待Token过期
Cookie和Session总结
| 方案 | 优点 | 缺点 |
|---|---|---|
| 单用Cookie | 服务端不需要做会话共享 | 客户端可以篡改状态信息,不安全 |
| Cookie+Session | 状态信息不会被篡改 | 需要做会话共享,增加集群耦合性 |
| JWT | 不需要会话共享,安全性高 | 无法主动废弃Token |
HTTP 1.1(主要版本)
HTTP 1.1发布于1999年,是目前使用最广泛的版本。
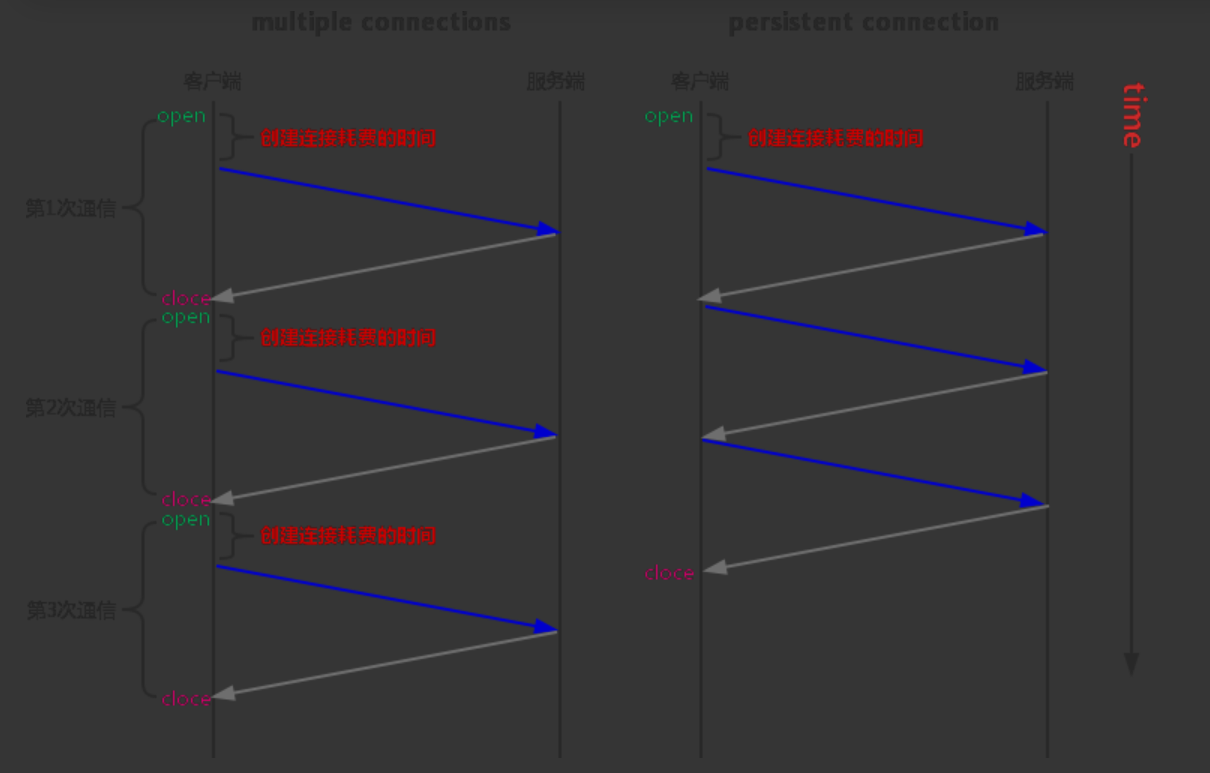
1. 长连接
- 默认所有请求都启用长连接
- 对应服务端需要设置
keepalive_timeout大于0
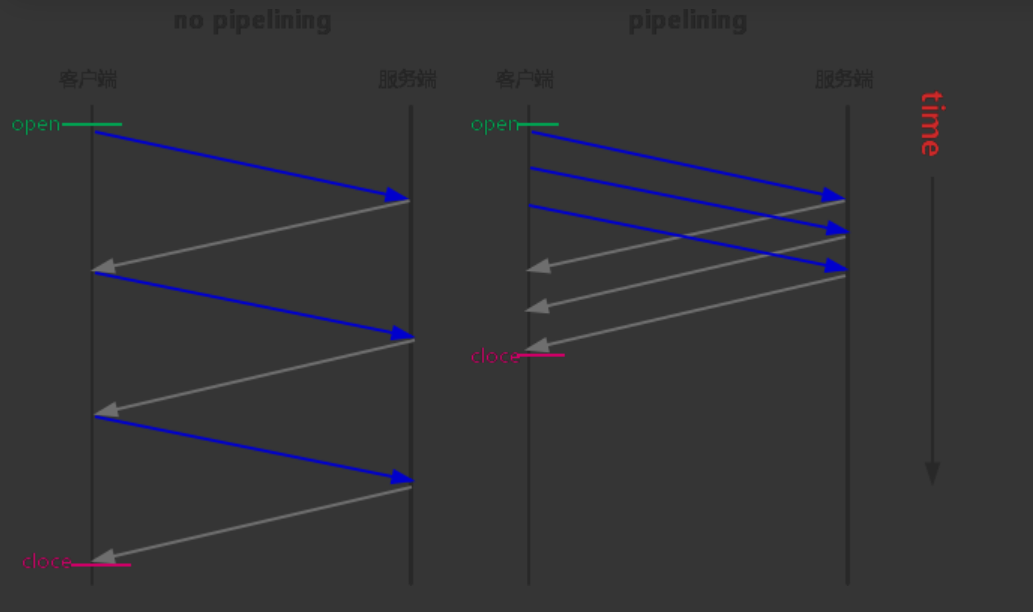
2. Pipelining(请求流水线化/管道化)
- 允许在同一个连接上发送多个请求而不需要等待响应
- 提高了传输效率
3. 分块传输编码(Chunked)
介绍
分块编码传输是一种允许服务器在不知道全部响应大小的情况下,通过多个"块"的形式逐步发送HTTP响应给客户端的技术。
标识方式
当响应头里包含 Transfer-Encoding: chunked,代表使用分块编码。
解决的问题
痛点:
当使用持久连接时,在服务器发送主体内容之前,必须计算出主体内容的大小,然后放到响应头里(Content-Length: 主体的字节数)发送给客户端。
如果服务器动态创建内容(比如由数据库动态产生的数据),可能在发送之前无法知道主体大小。
解决方案:
- 服务器把主体逐块发送,说明每一块的大小
- 服务器用大小为0的块作为结束块
- 响应头里不再需要Content-Length
关于Content-Length首部
1 | 如果请求头包含 'Accept-Encoding': 'gzip',则服务端会将内容压缩后返回, |
总结:
除非使用了分块编码 Transfer-Encoding: chunked,否则响应头首部必须使用 Content-Length 首部。
HTTP 2.0(未来趋势)
HTTP/2.0 的核心改进是大幅提升了传输效率。
主要特性
1. 二进制分帧
- 摒弃了HTTP/1.1的纯文本格式
- 采用二进制分帧,使数据传输更高效
2. 多路复用
- 允许在一个连接上同时处理多个请求和响应
- 彻底解决了HTTP/1.1的队头阻塞问题
3. 头部压缩
- 引入HPACK压缩算法
- 减少冗余数据开销
4. 服务器推送
- 支持服务器主动推送资源
- 显著降低延迟,加快网页加载速度
5. 请求优先级
- 允许客户端指定请求的优先级
- 重要资源优先加载
性能对比
| 特性 | HTTP/1.1 | HTTP/2.0 |
|---|---|---|
| 传输格式 | 文本 | 二进制 |
| 连接复用 | 有限(Pipelining) | 真正多路复用 |
| 头部处理 | 重复发送 | 压缩后发送 |
| 服务器推送 | 不支持 | 支持 |
| 队头阻塞 | 存在 | 解决 |
总结
发展历程
- HTTP 0.9(1991):最简单的版本,只支持GET方法
- HTTP 1.0(1996):引入多种请求方法、请求头、缓存
- HTTP 1.1(1999):长连接、管道化、分块传输,成为主流
- HTTP 2.0(2015):二进制分帧、多路复用、头部压缩,性能大幅提升
核心改进
- 连接管理:从短连接到长连接,再到多路复用
- 状态管理:从无状态到Cookie/Session/JWT
- 传输效率:从文本到二进制,从串行到并行
- 功能扩展:从简单获取到完整Web应用支持
选择建议
- 传统应用:HTTP/1.1 仍然足够使用
- 高性能要求:推荐使用 HTTP/2.0
- 未来趋势:HTTP/3.0(基于QUIC)正在发展中
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 ZephyrLu-Blog!